

一昔前まで、AIはクリエイティブな作業が苦手だと思われていました。そんな中、OpenAIがChatGPTを公開し、AIが言語を自由に操れることを世間に広めました。そして、AIが言語を自由に操れるようになったとき、AIが作り出せるのはテキストに留まらず画像や動画にまで拡張できることが明らかになりました。
既にAIは、学習データから全く新しい画像を作り出せる段階まで来ています。大企業、個人にかかわらず画像生成AIを使った新規サービスの開発競争を始めていますし、個々のITエンジニアが自身の業務に付加価値をつけるために活用しています。
本記事では、画像生成AIとして人気のStable Diffusionの特徴や、無料で利用する方法、利用時の注意点などを解説します。
Tech Forwardに登録されているAI分野の最新求人一覧を以下からご覧ください。
Stable Diffusionとは?

Stable Diffusionは、自然言語(テキスト)を基に画像を生成するAIモデルです。イギリスのStability AI 社が開発しました。オープンソースなので使用料はかかりません。
これまで、AIは対象物の特定や解析などといった「既にあるものを識別する」用途に利用されていました。しかしStable diffusionやChatGPTなどの「生成AI」は、学習したデータを基に「新たなものを生成」することができます。生成AIとは以下を指して呼ばれます。
画像を⽣成する拡散モデル(diffusion model)や⾃然⾔語を扱う⼤規模⾔語モデル(Large Language Model: LLM)などを指す。従来から識別モデルに対して⽣成モデルという分類法があり、その⽣成の側⾯に注⽬した呼び⽅。
出典:内閣府「AIに関する暫定的な論点整理」
従来のAIは業務効率化や単純作業の代替の手段として用いられてきましたが、生成AIを活用すればクリエイティブな創作活動が可能です。活用次第では、これまでDX推進に取り組めていなかった企業も、一気に後れを取り戻すことができると期待されています。
Stable Diffusionと並んで人気のある画像生成AIであるMidjourney、Dall-E 2を以下記事で比較しています。
こちらの記事でMidjourneyの仕組みについて詳しく解説していますので併せてご覧ください。Dall-E 2の仕組みはこちらをご覧ください。Midjourney、Dall-E 2、Stable Diffusionをこちらで一括比較しています。
Stable Diffusionがわかる7つの特徴

Stable diffusionの特徴は以下です。
- 無料で利用できる
- 商用利用も可能
- Diffusion Model(拡散モデル)を応用している
- Web・ローカルのどちらでも利用できる
- 画像生成だけでなく修復や拡張も可能
- 高度なカスタマイズが可能
- 多言語対応(完全ではない)
それぞれの詳細を解説します。
無料で利用できる
Stable Diffusionはオープンソースソフトウェア(OSS)であり、そのため無料で利用可能です。オープンソースとは、ソフトウェアのソースコードが公開されており、誰でもそのコードを利用、改変、再配布することが許可されている形態のソフトウェアです。この定義は、経済産業省が発表した「OSSの利活用及びそのセキュリティ確保に向けた管理手法に関する事例集」に基づいています。
OSSとは、ソフトウェアのソースコードが公開され、利用や改変、再配布を行うことが誰に対しても許可されているソフトウェアのことである。
出典:経済産業省「OSSの利活用及びそのセキュリティ確保に向けた管理手法に関する事例集」
画像生成AIには、多くの有料モデルや使用枚数に制限があるモデルが存在します。これらのモデルは、特定の商用目的や高度なカスタマイズが必要な場合には有用ですが、Stable Diffusionはそのような制限が一切ありません。
さらに、無料であるからといって生成される画像の品質が劣るわけではありません。Stable Diffusionは、そのオープンソースの性質と高品質な出力により、多くのユーザーにとってアクセスしやすい画像生成AIツールです。初期投資を抑えたい企業にとっては大きなメリットとなるでしょう。
商用利用も可能
Stable Diffusionは、商用目的での画像生成にも対応しています。このモデルはCreative ML OpenRAIL-Mライセンスの下で運用されており、このライセンスは商用利用を許可しています。
ただし、ライセンスはモデルの倫理的および法的な使用に焦点を当てています。したがって、モデルを法的かつ倫理的に使用する責任はユーザーにあります。特に、Stable Diffusionを自身のサービスに組み込む場合、エンドユーザーにライセンスのコピーを提供する必要があります。
また、Image to Imageなど、拡張性の高いStable Diffusionだからこそ可能な機能によって、著作権侵害の可能性もありますので、注意が必要です。
こちらの記事でStable Diffusionを商用利用する際の注意点について詳しく解説していますので併せてご覧ください。
Diffusion Model(拡散モデル)を応用している
Stable Diffusionでは、Diffusion Model(拡散モデル)という先進的な技術が採用されています。このモデルは、初めに学習データの画像に特定のノイズを加え、それが完全なノイズに変換されるプロセスを学習します。その後、画像生成時にはこのプロセスを逆に行い、ノイズから高品質な画像を生成します。
拡散モデルは、Stable Diffusionだけでなく、DALL·E 2、DALL·E 3やMidjourneyなど、他の多くの先進的な画像生成AIでも採用されています。特に、拡散モデルは「ノイズを除去する」または「画像を鮮明にする」(enhancing and refining)といった用途で非常に効果的です。
拡散モデルは、深層ニューラルネットワークを用いて、画像の潜在変数を学習します。これにより、モデルは画像の抽象的な概念を「理解」し、その知識を用いて新しい画像バリエーションを生成できます。この技術は、画像のノイズ除去や顔表情の操作、さらには人物の将来の顔の変化を予測するなど、多岐にわたる用途で活用されています。
Web・ローカルのどちらでも利用できる
Stable Diffusionは、Web上でのサービスとしても、ローカル環境での導入としても利用可能です。Pythonやコーディングの基本的な知識があれば、ローカル環境でシステムを自由にカスタマイズして動かすことができます。
Web上では、Stability AIが提供するDreamStudioやHugging faceのStable Diffusion Demoなど、複数のオンラインサービスがあります。これらのサービスは、最新バージョンのStable Diffusionモデルにアクセスでき、高速な画像生成が可能です。特にDreamStudioは、デフォルト設定で15秒以内に画像を生成できます。
ローカル環境では、Stable Diffusion WebUIやDiffusionBeeといったソフトウェアを用いてStable Diffusionを動かすことができます。これらのツールは、高度な設定やサンプリング方法の選択など、より詳細なカスタマイズが可能です。ただし、Pythonやgitのインストール、コマンドライン操作が必要な場合もあります。
Stable DiffusionのWebサービスは手軽さと速度を提供する一方で、ローカル環境は高度なカスタマイズとリソース管理の自由度を提供します。このような柔軟性も、Stable Diffusionが多くの専門家や企業によって高く評価されている理由の一つです。
Stable Diffusionを利用できるサービス
Stable Diffusionを利用できるサービスには、以下があります。
- Hugging Face
- Mage
- Dream Studio
Hugging FaceとMageはAIオープンソースのプラットフォームです。サイト内では、Stable Diffusion以外のモデルも利用できます。使い方はシンプルで、画像生成が初めての方でも直感的に利用できます。
Dream Studioは、Stable Diffusionの開発元であるStable AIが、Stable Diffusionのオープンβ版を公開しているサイトです。画像生成に慣れている人にとっては利用しやすいですが、初期画面でNegative Promptや画像のサイズなどを設定しなければならないため、初めて画像生成をする方にとっては少し難しいかもしれません。
画像生成だけでなく修復や拡張も可能
Stable Diffusionは、単なる画像生成以上の多様な用途で活用できます。特に、v1.2リリース以降、画像の修復(inpainting)と拡張(outpainting)の機能もサポートしています。
Inpaintingでは、画像内の特定の部分を選択し、テキストプロンプトを用いてその部分を修正することができます。特に小さな画像領域に対しても高い精度で動作するとされています。
Outpaintingでは、画像の元々の境界を超えて画像を拡張することができます。
高度なカスタマイズが可能
Stable Diffusionは、Fine-tuningとControlNetアーキテクチャを用いて、高度なカスタマイズが可能です。Fine-tuningは、特定の用途や限定的なトレーニングデータに対応するための手法であり、DreamboothやLoRAといった技術が存在します。これにより、ユーザーは自分自身の写真や異なるスタイルをモデルに適用することができます。
ControlNetは、オブジェクトの境界、線、スクリブル、ポーズのスケルトン、セグメンテーションマップ、深度マップなど、多くの要素でStable Diffusionを制御するためのアーキテクチャです。このアーキテクチャは、元のネットワークをクローンし、新しい入力条件を追加することで、元のネットワークを制御する新しいネットワークを生成します。
このような高度なカスタマイズ機能は、Stable Diffusionが多くの専門家や企業によって高く評価されている理由の一つです。
多言語対応(完全ではない)
Stable Diffusionは基本的に英語のテキストに最適化されていますが、その多様な応用範囲により、他の言語にも一定程度対応しています。
特に、AltDiffusionという多言語対応のText-to-Image Diffusionモデルが存在し、これは18種類の異なる言語をサポートしています。このような多言語対応は、Stable Diffusionがグローバルな市場での利用を広げるための重要なステップとなっています。
Web上で簡単にStable Diffusionを使う方法
ここでは、Mage(https://www.mage.space/)を用いてStable Diffusionを試します。
1. Stable Diffusionのモデルを選択する
Mageにアクセスすると、以下の画面が表示されます。
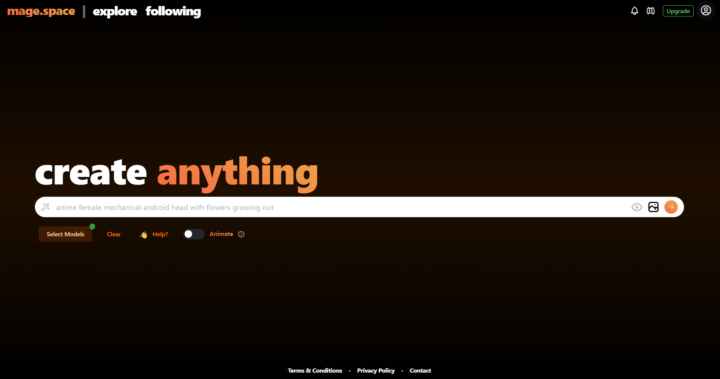
赤枠内の「Select Model」をタップすると、モデルを選択できます。ここでは、2023年9月現在、Stable Diffusionの最新モデルである「SDXL」を利用します。
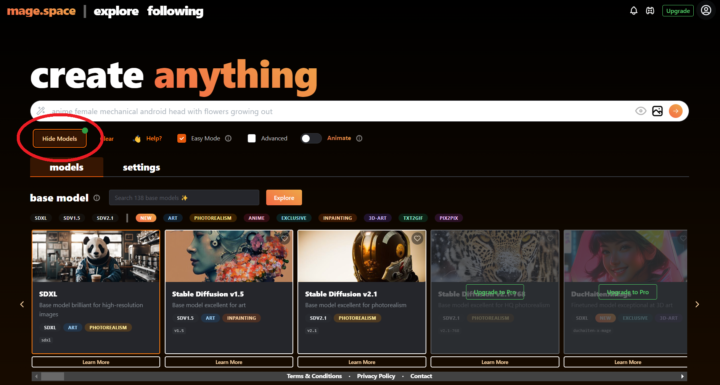
初期段階で利用したいモデルが選択されていれば、ここでの変更は不要です。
2. テキスト入力エリアに指示を打ち込む
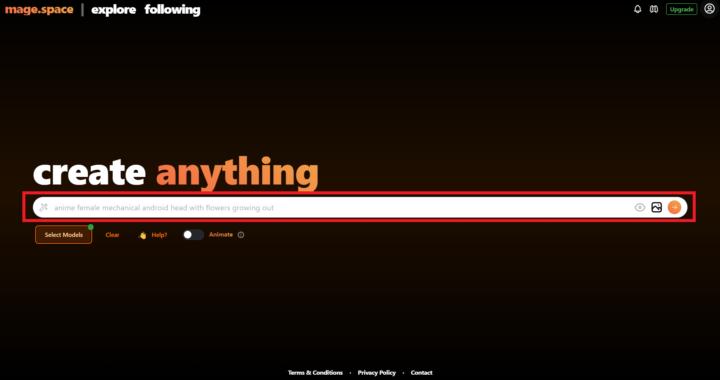
赤枠内のテキスト入力エリアに、どんな画像を出力したいかを入力します。一般的に、この指示のことをプロンプトと呼びます。
例として「Japanese woman walking her dog on a country road, best quality, photo, full body shot, 1girl, short hair, light brown hair, smile, hooded sweatshirt」と入力します。田舎道を飼い犬と一緒に散歩している日本人女性、という意味です。
どのモデルにも共通することですが、AIへの指示は可能な限り英語の方が良いです。特に海外で開発されたモデルは、日本語データよりも英語データで学習することが多いため、英語で指示したほうが精度が向上します。入力が完了したら、赤枠左端の右矢印ボタンで結果を出力しましょう。
3. 必要に応じて画像を改良する
以下のように結果が出力されます。
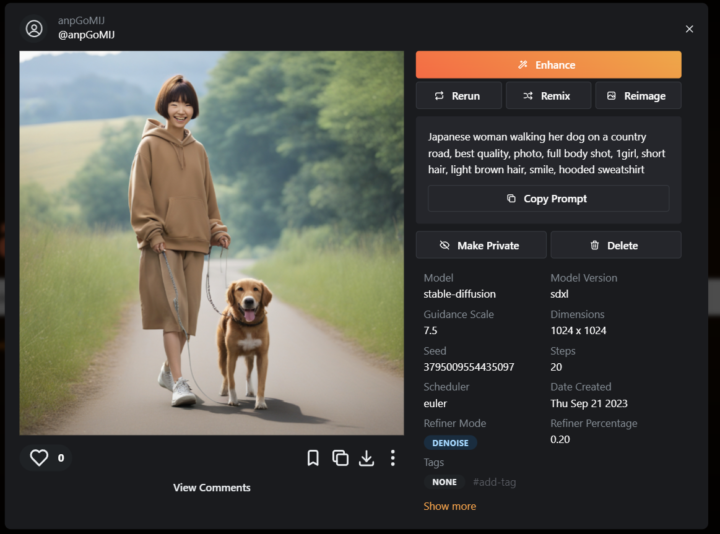
結果に不満があれば、「Remix」や「Reimage」を用いたり、プロンプトを作り直したりして改良しましょう。数回「Reimage」を繰り返すと、以下の画像になりました。
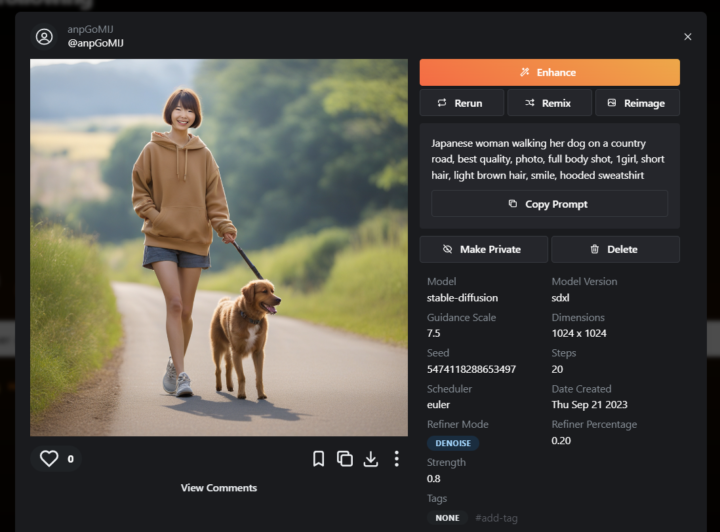
リールが3本から1本になるなど、改良されていることがわかります。しかし、画像生成AIの不得意分野である手・指はいびつなままでした。
おかしな点はあるものの、Stable Diffusionでは無料で簡単にオリジナル画像が生成可能です。学習データがさらに増え、精度が向上すれば、様々な事業に活用できるかもしれません。
Tech Forwardに登録されているAI・Web3分野の最新求人一覧を以下からご覧ください。
Stable DiffusionをLoraで学習させる方法
Stable Diffusionは、さまざまなモデルを利用して、特定のプロンプトを入力することで、ユーザーが思い描いた画像をAIによって生成するシステムです。しかし、このプロンプトにも限界があります。
例えば、版権キャラクターや特定の衣装・画風を再現する場合、単にプロンプトを入力するだけでは、理想の画像を生成するのが難しいことがあります。
そこで重要になるのが『Lora』モデルの活用です。『Lora』は“Low-Rank-Adaptation”の略で、既存のモデルに対して、特定の画像(例えば版権キャラクターや特定の衣装・画風)を追加学習させることができるモデルです。
『Lora』を活用することで、従来は難しかった特定のキャラクターやスタイルの再現が容易になります。ただし、版権物の使用には注意が必要で、特に商用利用の際は権利関係を十分考慮する必要があります。
『Lora』を利用するメリット
『Lora』を利用することで、以下のような多彩なメリットがあります:
- イラストの画風調整:『Lora』を使用すると、アニメ風、カートゥーン風、3D風など、様々なスタイルに画像を調整できます。
- 特定の人物やキャラクターの画像生成:同一人物やキャラクターの画像を複数生成することが可能です。
- カスタマイズ可能な外見:服装、髪型、背景、ポーズなど、特定の要素を自由に設定して画像を生成できます。
『Lora』モデルを入手できるサイト
『Lora』ファイルを配布している主なサイトは次の2つです。
- Hugging Face:幅広いAIモデルが公開されています。
- civitai:AI画像生成の例やプロンプトが豊富に紹介されており、特におすすめです。
これらのサイトを利用して、好きなキャラクターやスタイルの画像を検索し、生成の楽しさを体験してみてください。グローバルなサイトであるため、英語や中国語など様々な言語での検索が効果的です。
Stable Diffusion使用時の注意点

Stable Diffusionは非常に便利な画像生成AIですが、利用時には以下の注意点があります。
- 著作権を侵害しないようにする
- 同じプロンプトでも異なる画像が出力される
- 高性能なPCが必要
- 高品質な画像を出力するにはコーディングスキルが必要
それぞれについて解説します。
著作権を侵害しないようにする
画像生成AIを誤った方法で利用すると、著作権を侵害する可能性があります。多くの場合、Stable Diffusionで生成した画像を公開・販売しても、著作権を侵害することはありません。しかし、既存の著作物との「類似性」または「依拠性」が認められなければ、著作権を侵害することとなります。
AIが生成した画像でも、「類似性」または「依拠性」が認められれば、利用の際には著作権者の許可が必要です。これに違反した場合、差止請求や損害賠償請求をされる可能性があります。
故意の場合は、刑事罰を科せられる場合もあります。よって、見覚えのある画像をAIが生成した場合は、著作権者に許可を取ったり、大幅に手を加えたりするなどの対応が必要です。
また、最も注意すべき点として、Image to Image (i2i)で画像生成した生成物が挙げられます。Image to Imageの場合、入力した画像の特徴が出力結果に大きく影響します。よって、入力画像が著作物である場合は、著作権侵害のリスクが非常に高くなります。
Stable Diffusionでは、Image to Imageの生成が可能です。利用する際は、著作権フリーの画像を使うなど、細心の注意を払うようにしてください。
合わせて、追加学習されたLoRAを利用する際も、著作権には注意が必要です。
同じプロンプトでも異なる画像が出力される
Stable Diffusionに同じプロンプトを入力しても、毎回異なる画像が出力されます。これは、画像の基であるノイズが異なるためです。
ノイズには無数のパターンが存在します。同じノイズが割り当てられれば同じ画像が生成されますが、それまで生成し続けるのは現実的に考えて不可能です。よって、希望通りの画像が生成できたら、その場で保存するようにしましょう。
高性能なPCが必要
ローカル環境でStable Diffusionを動かす場合、高性能なPCが必要です。CPUに関しては、intelの「Core i5」、AMDの「Ryzen5」以上であれば問題なく動くという声が多いです。(但し、生成に時間を要する場合が多くあります。)例外はありますが、性能が低いと言われている「Celeron」「Pentium」では動作に支障をきたす可能性が高いです。
メモリに関しては、Stable Diffusion公式は16GB以上を推奨しています。ただし、高負荷な作業を行いたい場合は、32GB以上あると安心です。
グラボ(グラフィックボード)に関しては、基本的にVRAM容量を見ておけば問題ありません。Stable Diffusion公式は、4GB以下で動作させるとエラーが出る可能性があると言及しています。しかし実際には、快適に利用するために8GB、高負荷な作業を行う場合は12GB以上の容量が必要でしょう。
これらの環境が用意できない場合は、Web上のサービスを利用するようにしましょう。
高品質な画像を出力するにはプロンプトスキルが必要
高品質な画像を出力するには、AIへ的確な指示(プロンプト)を入力する必要があります。Stable Diffusionであれば、写真の雰囲気に加えて「Realistic」や「RAW photo」と入力すると、写真のような仕上がりになります。
的確な指示(プロンプト)は、AIの力を最大限活かすことに繋がります。既に、この技術を提供する「プロンプトエンジニア」という職業も出てきています。プロンプトエンジニアとは、PythonやCといったプログラム言語ではなく、自然言語(私たちが普段使っている言葉)をコードするエンジニアです。
詳しくは「プロンプトエンジニアとは?なぜ人気?仕事内容・年収と必要なスキル・将来性を詳しく解説!」で解説していますので、興味がある方は参考にしてください。
Tech Forwardの姉妹サービスであるPrompt Plusは、プロンプトエンジニアの作成した高品質なプロンプトを売買可能なプロンプトマーケットプレイスです。プロンプトの販売や購入にご興味のある方はぜひご覧ください。
プロンプトマーケットプレイス|Prompt Plus
Stable Diffusionでよくある質問まとめ
- Stable Diffusionとは?
-
Stable Diffusionは、自然言語(テキスト)を基に画像を生成するAIモデルです。Stable diffusionやChatGPTなどの「生成AI」は、学習したデータを基に「新たなものを生成」することができます。詳しくはこちらにジャンプ。
- Stable Diffusionの特徴は?
-
Stable diffusionの特徴は、以下の3つです。
- 無料で利用できる
- Diffusion Model(拡散モデル)を応用している
- Web・ローカルのどちらでも利用できる
詳しくはこちらにジャンプ。
まとめ
画像生成AIであるStable Diffusionの特徴や、Web上で利用する方法、利用時の注意点などを解説しました。これまでイラスト制作を外注していた方や画像制作に多くの時間を割いていた方は、Stable Diffusionなどの画像生成AIを活用することで、経費削減や業務効率化に役立てられるかもしれません。
また、様々なAIの出現により、AI関連の人材が不足しています。経済産業省は、2030年に最大で79万人ものIT人材が不足すると予測しています。本記事では自然言語を扱う「プロンプトエンジニア」に触れましたが、AI技術が急成長している今、AI関連の職業へ転職するチャンスが増えています。
Tech Forwardでは、AI分野の求人を多く掲載しています。転職をお考えの方は、どのような職業があるのかを確認してみてはいかがでしょうか。
Tech Forwardに登録されているAI・Web3分野の最新求人一覧を以下からご覧ください。
Tech Forward公式Discordには、AI・Web3・メタバースなど先端テクノロジーに興味のある方が集まっています。最新テクノロジー情報のキャッチアップや、同じ興味分野がある方との人脈づくり、最新技術活用の議論、お仕事情報GETが可能です。ぜひ気軽にTech Forward公式Discordにご参加ください!
Tech Forward Magazine編集局では、AIやWeb3、ブロックチェーン、メタバース等に関するお役立ち情報を発信しています。姉妹サイトのAI Market(https://ai-market.jp/)やPrompt Plus(https://prompt-plus.ai/)の案内も行います。
