

2023年6月22日(木)に、Tech Forward Discordコミュニティにて、「現役AIエンジニアと学ぶ!画像生成AIの最新論文から最新テクノロジー動向を知ろう!」と題し、昨今の生成AI(ジェネレーティブAI)の流れを最新の論文を通して先読みすることができる勉強会イベントを開催しました。
本記事では、当日ご参加頂けなかった方に向け、イベント内容を抜粋してご紹介します。
イベント概要
- イベント名:現役AIエンジニアと学ぶ!画像生成AIの最新論文から最新テクノロジー動向を知ろう!
- 開催日時:2023年6月22日(木)20時
- 開催場所:Tech Forward Discordコミュニティ内イベント会場
(参加はこちら:https://discord.gg/fzuKcprg3v) - 登壇者
発表:大手IT企業 機械学習リサーチエンジニア yuchi
モデレーター:BizTech株式会社 代表取締役 森下 佳宏 Twitter
イベント内容
本イベントは、Tech Forward Discordコミュニティ内イベント会場にて開催されました。
開催の様子はこちらをご覧ください。
以下は、yuchiさんの発表の抜粋です。
まずは生成AIを理解する上で欠かせない基盤モデルについての説明がありました。
基盤モデルは、これまでの1モデル-1タスクのAIモデルと異なり、1モデル-複数タスクをこなすことが可能なモデルです。
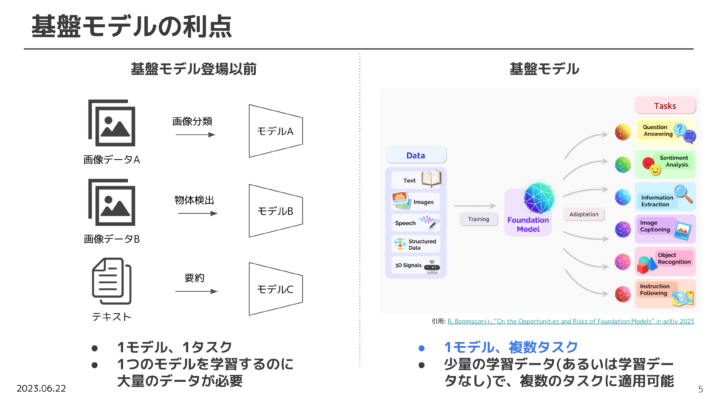
ハードウェア能力の向上や、Transformerというモデルの発明等を通して、基盤モデルが拡充したことで、昨今話題のChatGPTやDALL-E等の生成AIに結びついていきました。

そして実際に生成AIにおける最新の研究事例をいくつか発表頂きました。
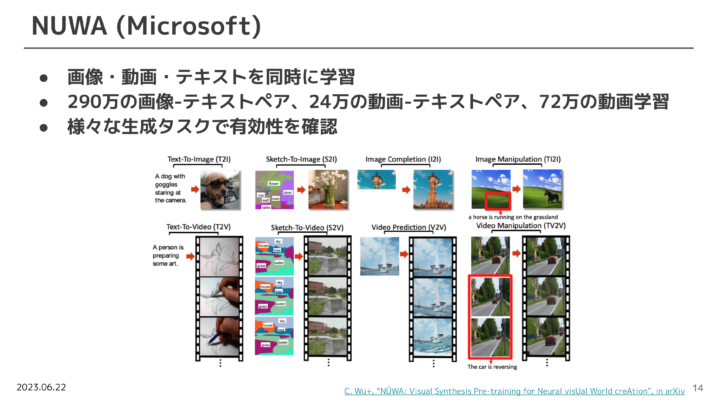
Microsoft社のNUWAと呼ばれるプロジェクトでは、Text to Image や Text to Text だけでなく、Sketch to ImageやImage manipulationといった研究が行われています。
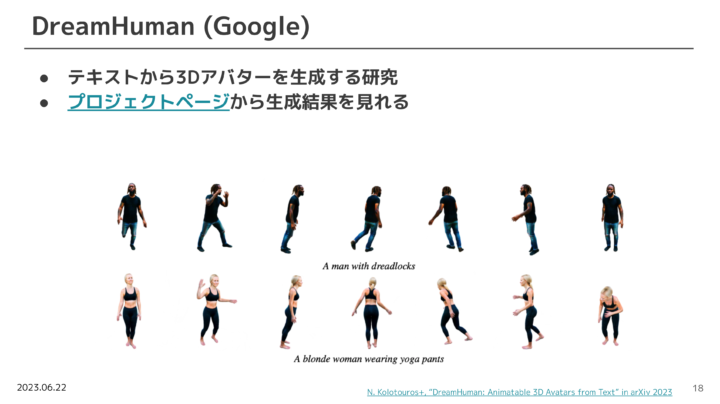
Google社が行っているDreamHumanというプロジェクトでは、テキストから3Dアバターを生成する研究が行われています。
この3Dモデルでは、外観、服装、肌の色、体型など細部に渡るところまで、精緻に3Dアバターとして生成することが可能です。
プロジェクトページ:https://dream-human.github.io/
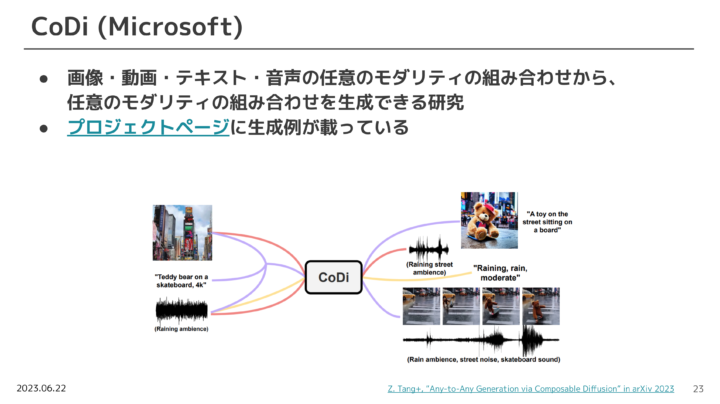
他にも、CoDiというMicrosoft社の研究についても教えて頂きました。
このモデルは、画像・動画・テキスト・音声といった複数のモダリティの組み合わせから、任意の組み合わせでの生成ができるモデルです。
このプロジェクトは非常にユニークで、例えば下記のスライドにもあるように、都心部の画像+「スケートボードに乗ったテディベア」というテキスト+雨の音を入力すると、「都心部で雨の中、スケートボードに乗ったテディベアが走っている動画」が出力されます。詳しくはプロジェクトページをぜひご参考ください。
プロジェクトページ:https://codi-gen.github.io/
このような形で、生成AIの基本である基盤モデルについて、そして最新の生成AI関連の論文・プロジェクトを発表頂く大盛況のイベントとなりました。
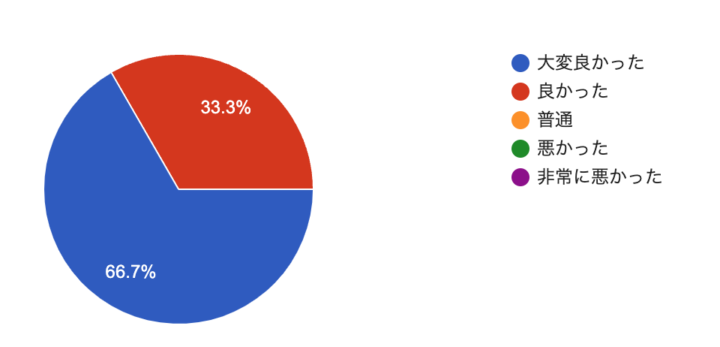
参加頂いた方のアンケート結果
イベントアンケートでは、参加にご満足頂けたという方が非常に多くなりました。
また実際に下記のようなお声を頂いております。(抜粋)
様々な機械学習モデルを知れて良かった。
最新の生成AIの動向がわかりやすかった。
Discordになれておらず、最初10分程度音声が聴こえなかったため。内容はとても勉強になり、良かったです。
まとめ
今回は、昨今話題の生成AIに関する最新研究を学ぶ勉強会を開催しました。
今後もTech Forwardでは、同様のイベントを開催していきたいと思いますので、イベント情報を見逃さないためにも、AI / Web3に興味のある方が集まるTech Forwardコミュニティへぜひご参加ください!
(勉強会資料もDiscord内にて共有しております。)
Discordコミュニティへの参加はこちら:https://discord.gg/fzuKcprg3v
Tech Forward Magazine編集局では、AIやWeb3、ブロックチェーン、メタバース等に関するお役立ち情報を発信しています。姉妹サイトのAI Market(https://ai-market.jp/)やPrompt Plus(https://prompt-plus.ai/)の案内も行います。
